Evaluate
Evaluate your queries offline.
The evaluation page allows offline evaluation of queries and provides a quick and easy way to test Inconvo’s capabilities on your data and your users’ queries, even before you deploy Inconvo to production.
Test cases
Section titled “Test cases”Each row in the evaluations table is a test case. Add a new test case by inputting a question in the input box beneath the table.

Test cases will initially be marked as for Review
They can then be marked as Passing or Failing by clicking on the test case row and opening the trace view.
You can use the evals table to debug failing test cases and build towards an acceptable test pass rate for your application.
Traces
Section titled “Traces”For every evaluation query a trace is created. A trace shows the steps Inconvo took to create an answer.
Traces show the tools Inconvo used for the run, their input_options, the tool call and the output.
Debugging Example
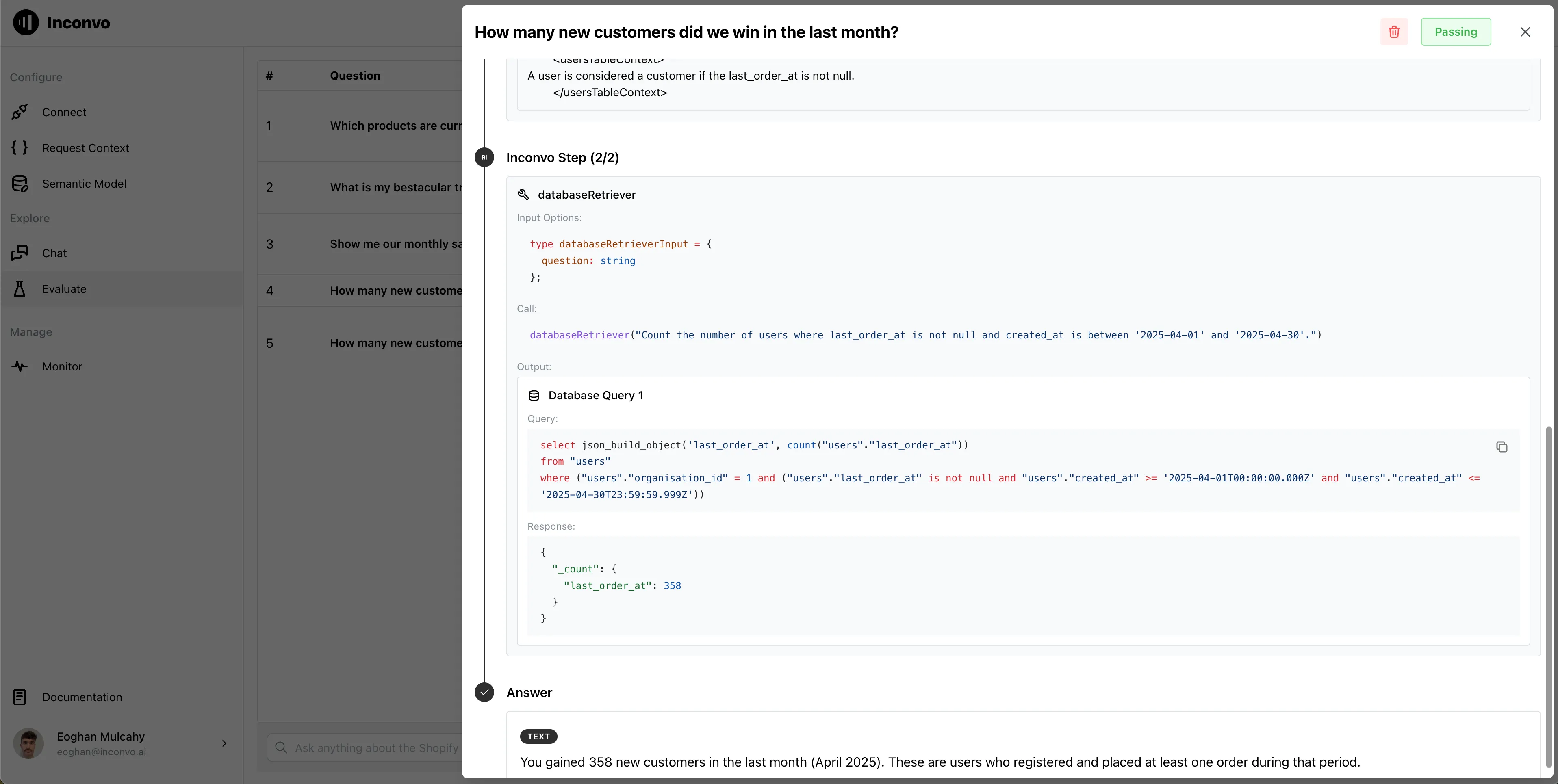
Section titled “Debugging Example”How many new customers did we win in the last month?
Looking at the trace we see that Inconvo used the number of users created in the last month to answer the question.
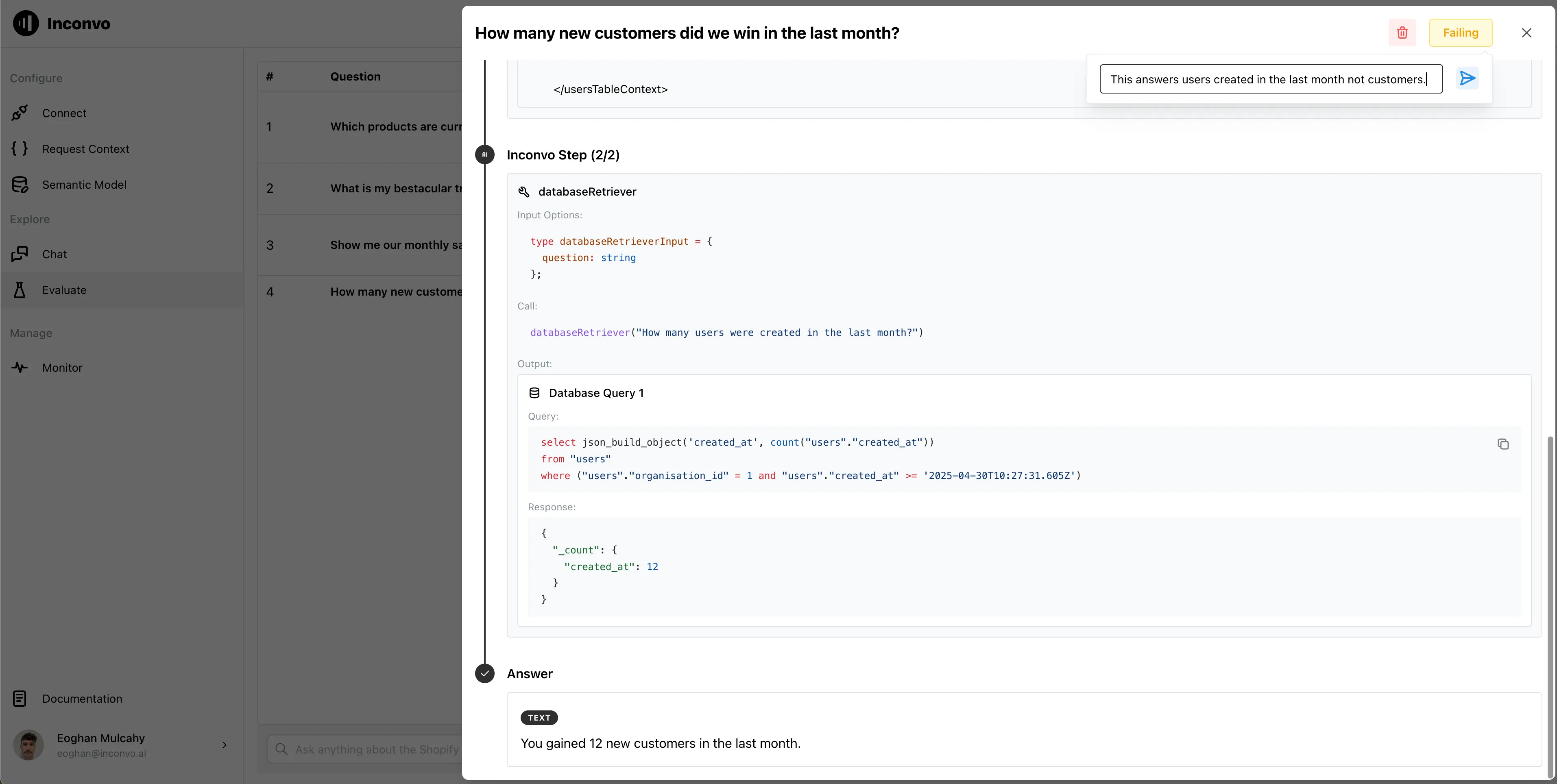
In our application users != customers so the answer is incorrect and we mark the run as failing.
The fix is simple, add a table prompt to the users table to inform Inconvo of what a customer is in our application.
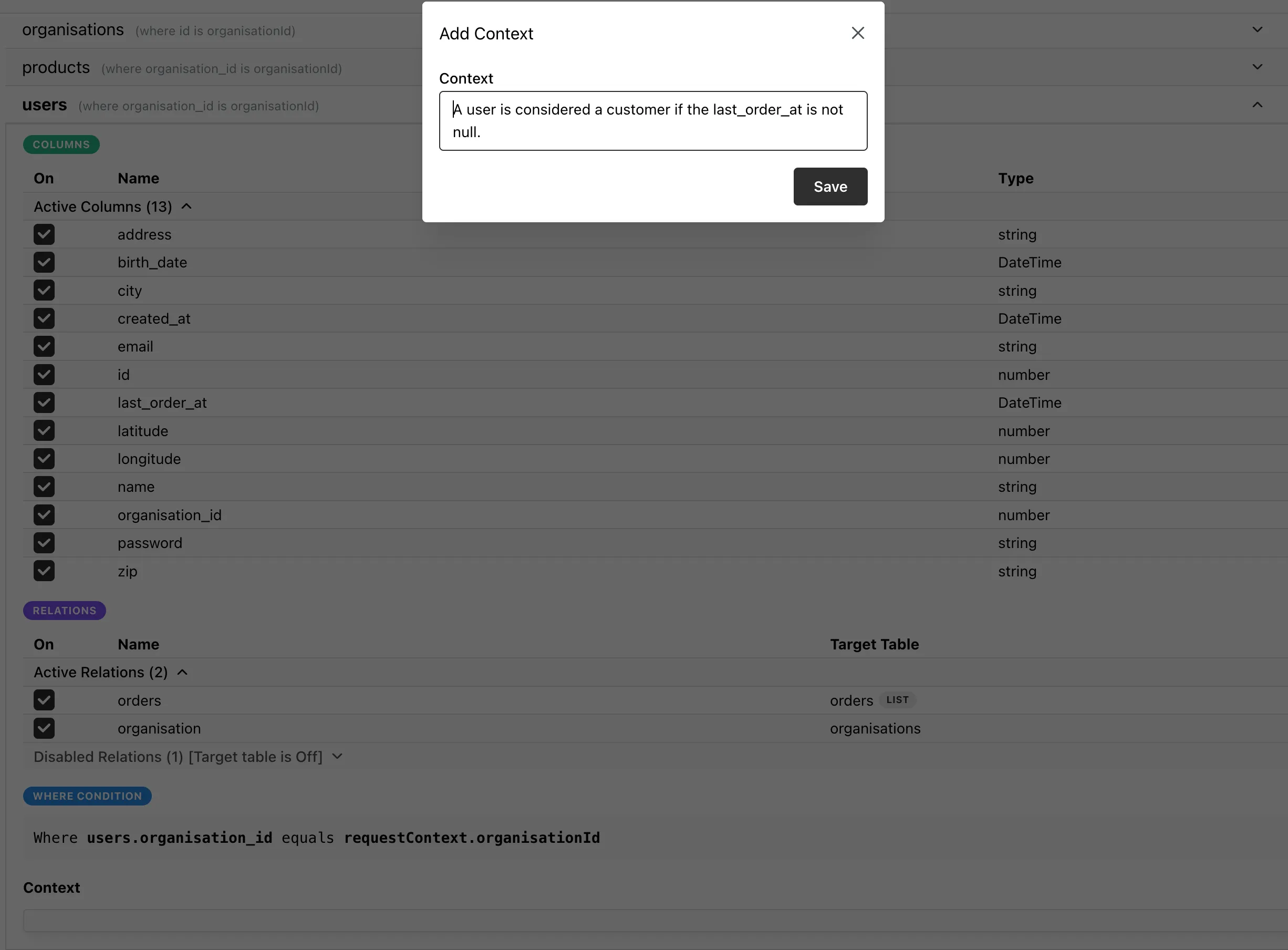
With this simple addition Inconvo retrieves the correct answer and we mark the test case as passing.